I’m currently looking at the performance issues of an internal Java webapp being developing at the University. It’s a large piece of software (over 374 Java files) which has ‘naturally’ evolved over the years meaning that many requirements have changed since it was originally conceived leaving the software with a fair amount of feature bloat.
Rather then re-engineer the entire beast (even assuming I could get my head around it all) I’m first tackling all the low hanging fruit I can find. The reasons for this approach are:
- Do the work that delivers the quickest reward (time is money after all). This also lets customers see immediate results.
- I’ve only just joined the project so this approach helps me gain a better understanding of the ins and outs of the software.
- The simple changes have (hopefully) the least amount of negative impact (we are not using TDD here – there is no software I can rely on to tell me if any of my changes break existing code)
- Resolving all the simple issues will help highlight what’s remaining (which will tend to be more serious architectural issues).
Dipping my toe in the water I first tackled a certain page that was taking over 10mins to complete. Using VisualVM it became clear that memory was not being used efficiently. In this case we were inefficiently manipulating strings (applying 27k diff patches to a large lump of text) using the DiffMatchPatch library. Essentially switching from String to StringBuilder allowed the page to render in 40 seconds and use around 100Mb memory (rather then continually chomp all the way through the 1Gb I’d given tomcat).
My focus next moved to the gson library. We use this library to store json representations of versioned objects in the database. Most of these strings are small (50-500bytes) however a few extend to 20k, 60k and even 1.8Mb in size. We currently use gson version 1.4. The latest stable release is 1.7.1 and trunk has now moved onto 2.0. I checked out the code (r994) – after filing a bug report to the gson developer to support null values – compiled the trunk and then wrote some tests to convert some of our larger json-efied strings into objects (fromJson()) and back to json strings again (toJson()), then comparing the two json representations using the Jackson parser (which ignores the ordering of properties). Once I had the tests passing, I wrapped Perf4j around the fromJson() calls and was able to generate the following graph by repeatedly converting objects using the 1.4, 1.7.1 and 2.0 libraries in order:
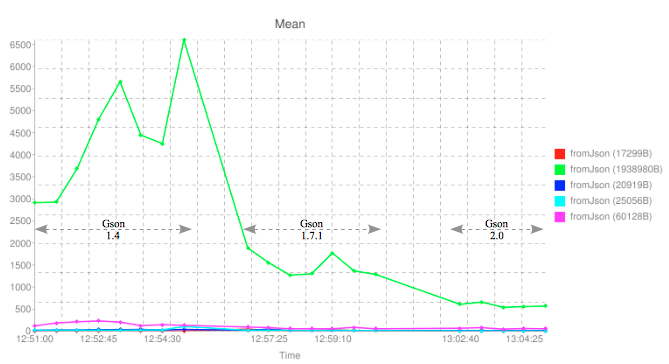
On the graph above, the y-axis represents the average time in milliseconds to call the fromJson() function with objects of different sizes (see the legend for the size of each object in bytes). We can see that things are looking good. Clearly newer versions of the library get consistently better (faster) at converting very large objects.
Unfortunately the largest object (1.8Mb) dwarfs the other results. If I remove this from the results I can more easily drill down into the remaining figures.
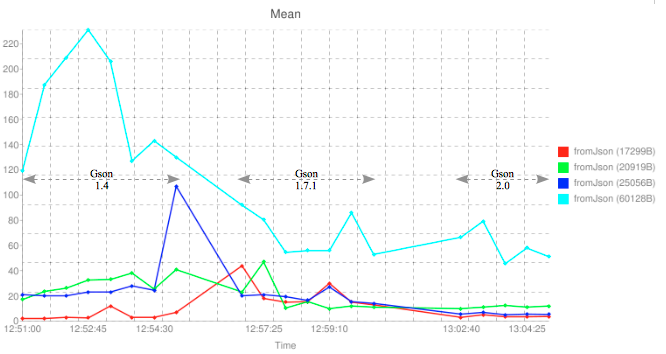
Again you can clearly see the next largest object (60k) gains significant speed improvements with increasing gson library versions. After that however, things become a little less clear. The entities around 20k show little, if any improvement. It’s interesting to note that for the smallest object in my test (17k) shows worse performance under the 1.7.1 version of the library.
I the take-home message here is that the gson library continues to get better and better with each new release, however you’ll probably only really notice this improvement if your dealing with relativity large entities (in my case over 20,000 bytes in length).
N.B Speed is of course only half the story. I haven’t taken memory management into consideration. My naive attempts to measure it with Runtime.getRuntime().totalMemory() didn’t show any significant improvements but I have no doubt that 2.0 employs more efficient memory usage.
Next on the agenda is method caching…