Our lives have become intwined with the maelstrom of digital connections happening all around us. Having given us the digital age, kicked off the web and brought about our modern world of rolling news, twitter trends and Facebook ‘likes’, computer scientists are starting to offer something back to traditional Science; the tools and methodologies it needs to conduct Science in the 21st Century. Continue reading
Author Archives: Chris Bailey
LinkedData hackday event
I’ve just finished attending a DevCSI+Research Revealed linked data hackday event. This 2 day event hosted by ILRT, was a chance for like-minded individuals interested in Linked Data to meet up, chat, listen to presentations, lightening talks and get a chance to do some hacking together.
We had around 40 attendees from a range of backgrounds; including local freelance developers, software houses, public and private sector companies, members of HE institutions & PhD students.
Over the two days there was a wealth of new ideas, techniques and tools presented, including…
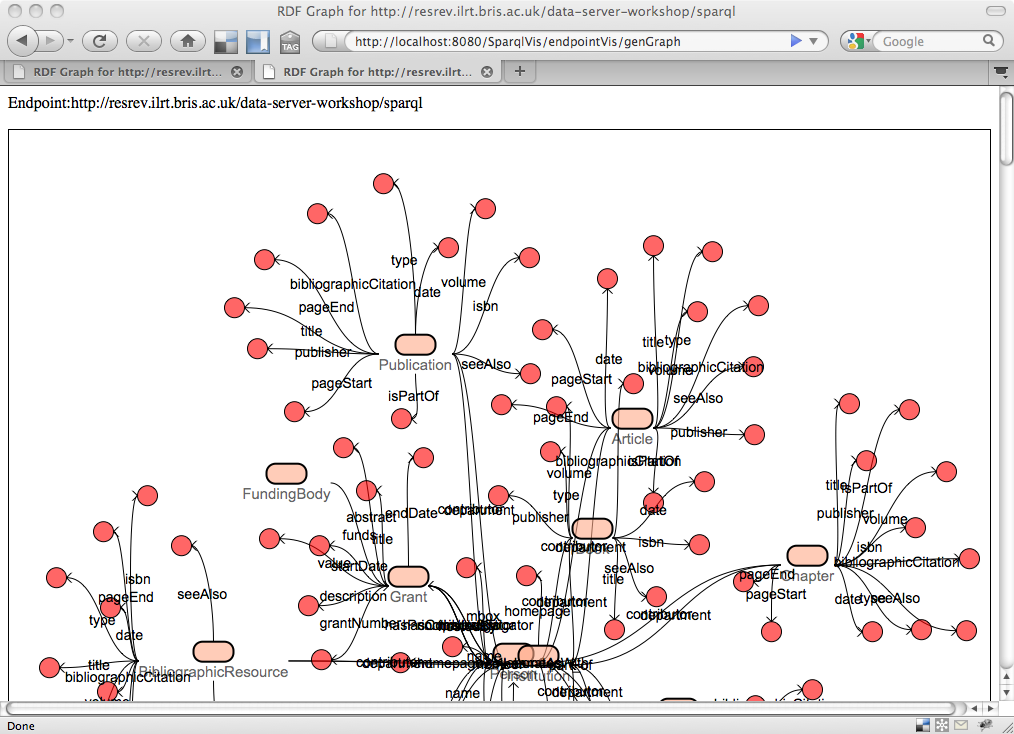
For the hacking part of the event, I teamed up with Libby Miller, Damian Steer and Sam Adams to look at characterising large datasets. In my view this is an underrated aspect of Linked Data which can help increase adoption – how to gain an understanding and feel for the data lying behind an Endpoint when all you can do is fire off unfriendly SPARQL/REST queries. We were investigating techniques for feature extraction/statistical analysis of RDF graphs, and looking at tools to provide visualisations of the datasets. Initially we experienced a few frustrating hours as we came to realise that although we know little of graph theory, it was clear that even to experts this is a non-trivial set of problems.
We struggled on and by the end of day 2, Damian and I successfully implemented a graph reduction algorithm which could be used to identify isolated sub-graphs from within a network of triples.
Spurred on by this work, after the event I coded up a RDF Class-Property diagram viewer using Grails and the Dracula Graph Library, based on Chris Gutteridge‘ SPARQL Vampire Diagram generator.
SKOS Cheat sheet
Due to lack of a better alternative, I’ve created a cheat sheet for Simple Knowledge Organization System (SKOS) terms. Continue reading
DrupalCamp Bristol 2010
On Saturday (27th March) I attended a DrupalCamp Bristol event, the first gathering of Druapl-ers in the South West.
Over 45 people attended the day, which included a lot of people from the hosts, SiftGroup, and the rest seemed mainly freelancers. Also in attendance was Matt Hamilton who was on the lookout for tips on the organisation of the event in light of the upcoming Plone conference later in the year.
The day consisted of about 4, 40 minute talks and plenty of time in between for informal chats. People could also post up requests for impromptu talks, and Matt gave us all an introduction to Plone for Drupal developers.
I found the day generally interesting, and enjoyed the out-of-talk discussions.
Although the talks themselves were not massively useful, I have come away with the desire to look into:
* Xdebug (a php profiler)
* Drupal 7’s integrated support for caching (APC, Memcached, reverse proxies – generally the stance is to play well with tools designed for this task)
* Pressflow (a distribution of Drupal with integrated performance, scalability, availability, and testing enhancements)
* install profiles & features – the ability to record multiple module settings and reapply them in bulk
* Admin – a decent? admin interface
All in all I though the day was well worth attending, just a shame I had to leave before the security talk!
Android app out now
I’ve just released my first Android mobile phone application 🙂
“This app shows you nearby petrol stations and lets you share fuel prices for petrol stations that you know of, and to see the prices entered by others.
Browse the map to find stations, and click any station flag to view and update prices.
For more information, check out the WhatGas web site:
http://www.whatgas.com”
Download from the Android Market today, or visit my website for more information.