I’ve just finished attending a DevCSI+Research Revealed linked data hackday event. This 2 day event hosted by ILRT, was a chance for like-minded individuals interested in Linked Data to meet up, chat, listen to presentations, lightening talks and get a chance to do some hacking together.
We had around 40 attendees from a range of backgrounds; including local freelance developers, software houses, public and private sector companies, members of HE institutions & PhD students.
Over the two days there was a wealth of new ideas, techniques and tools presented, including…
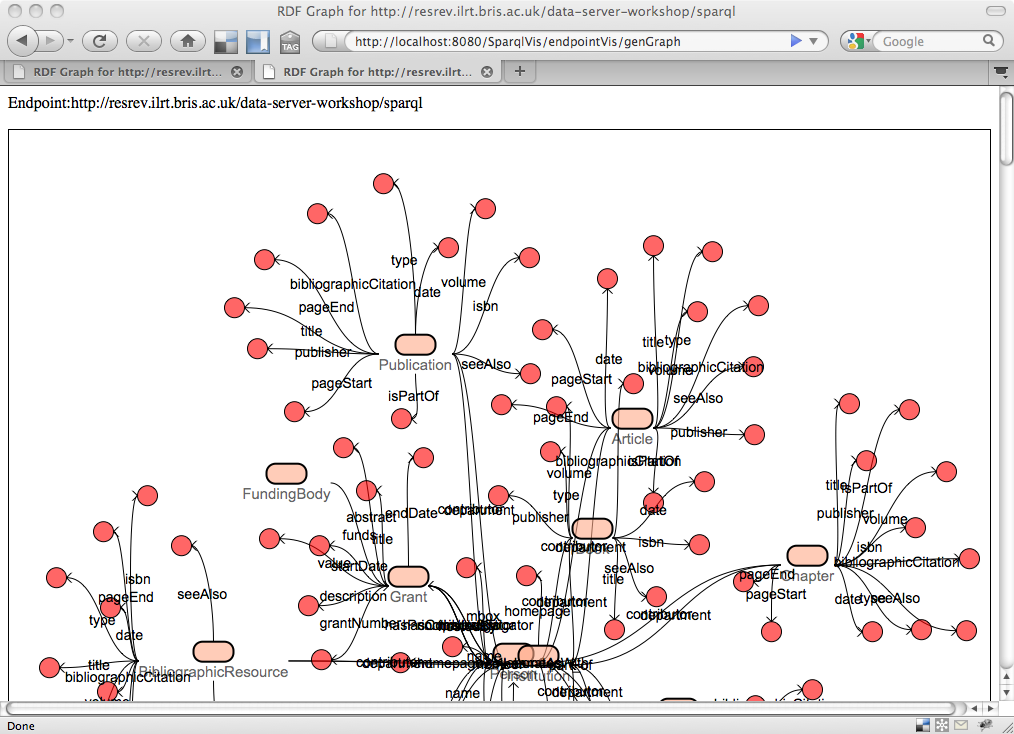
For the hacking part of the event, I teamed up with Libby Miller, Damian Steer and Sam Adams to look at characterising large datasets. In my view this is an underrated aspect of Linked Data which can help increase adoption – how to gain an understanding and feel for the data lying behind an Endpoint when all you can do is fire off unfriendly SPARQL/REST queries. We were investigating techniques for feature extraction/statistical analysis of RDF graphs, and looking at tools to provide visualisations of the datasets. Initially we experienced a few frustrating hours as we came to realise that although we know little of graph theory, it was clear that even to experts this is a non-trivial set of problems.
We struggled on and by the end of day 2, Damian and I successfully implemented a graph reduction algorithm which could be used to identify isolated sub-graphs from within a network of triples.
Spurred on by this work, after the event I coded up a RDF Class-Property diagram viewer using Grails and the Dracula Graph Library, based on Chris Gutteridge‘ SPARQL Vampire Diagram generator.